FlowSeg4D: Unsupervised 4D Panoptic Segmentation
An online framework for 4D panoptic segmentation of LiDAR driving scenes that requires no labeled training data. It combines semantic segmentation, scene flow estimation, and temporal clustering to produce consistent instance tracks across time — rivalling supervised methods on the SemanticKITTI and nuScenes benchmarks.
Method
4D panoptic segmentation extends panoptic segmentation to temporal sequences — each point must be assigned both a semantic class and a consistent instance identity across frames. FlowSeg4D achieves this without any labels by combining three components.
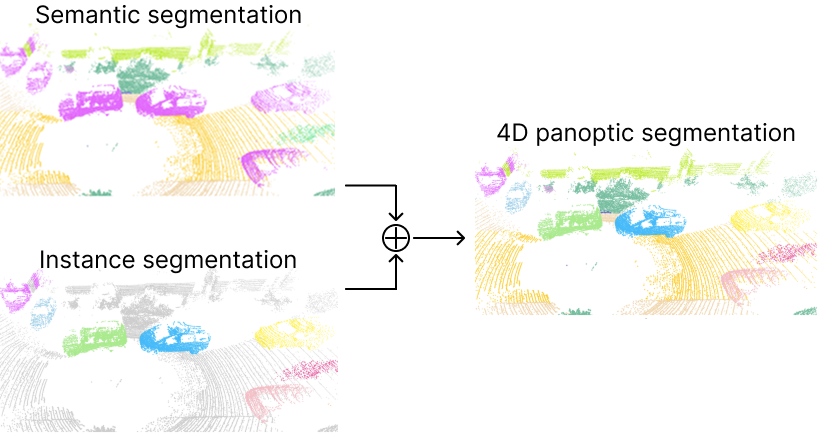
The 4D panoptic segmentation task
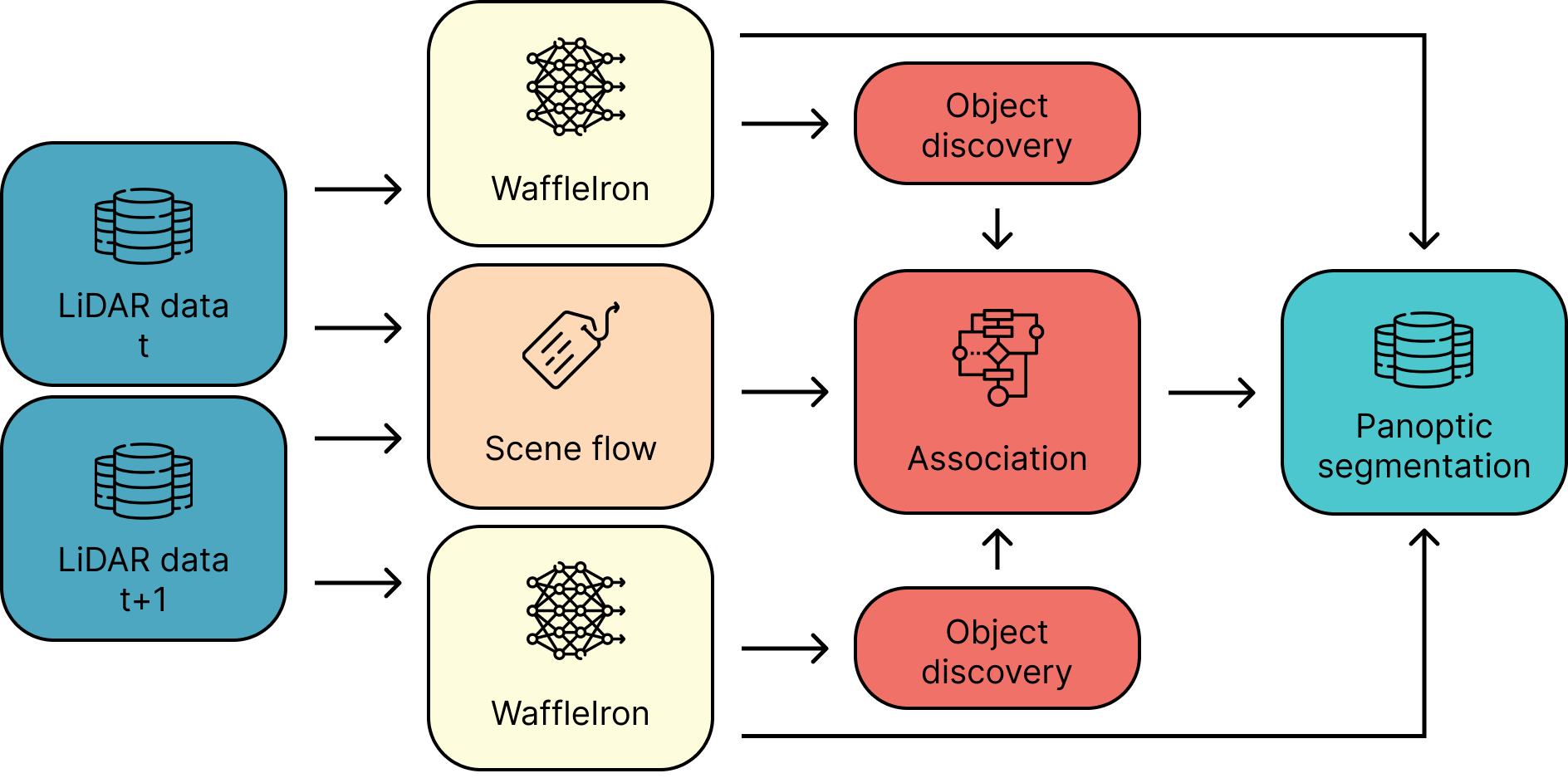
FlowSeg4D pipeline — semantic segmentation (yellow), scene flow (beige), instance association (red)
Semantic segmentation
WaffleIron WI-48-768, pretrained unsupervised via ScaLR on four LiDAR sensor types using DINOv2 features. Linear probing on the target dataset provides class labels while keeping annotation requirements minimal.
Scene flow estimation
Let-It-Flow — an unsupervised optimisation-based model selected for low error on vulnerable road users (pedestrians, cyclists). Flow vectors are precomputed and used by the association module to update cluster positions before matching.
Instance association
A clustering and Hungarian-matching module that links object clusters across frames. The long-term variant maintains a temporal window of previous frames and uses WaffleIron embeddings alongside spatial distance to resolve ambiguous matches.
Association pipeline
Four progressively richer association strategies were developed and evaluated. All share the same clustering step; they differ in how clusters are matched across frames.
Naive
- Cluster foreground semantic points per class (ALPINE / DBSCAN / HDBSCAN)
- Hungarian match between current and previous frame using cluster-centre distance as cost
- Accept match if distance < 3.5 m → assign same instance ID
Fast and interpretable, but limited to one previous frame and struggles with occlusions.
Naive + Scene Flow
- Shift cluster centres by the mean scene flow vector before matching
- Otherwise identical to Naive
Improves SemanticKITTI scores but hurts nuScenes — most effective when semantic labels are noisy.
Long-term window Best
- Maintain a window of N previous frames (optimal: 6)
- Represent each cluster by its mean WaffleIron embedding
- Cost matrix = cluster-centre distance + feature dissimilarity (1 − cosine similarity), weighted by α = 0.1
- Hungarian match; accept only if both distance (< 4.5 m) and feature thresholds (dissimilarity < 0.4) pass
Consistent improvement over Naive across all datasets and clustering methods.
Long-term + Scene Flow
- Update previous-frame cluster centres with mean scene flow before matching
- Otherwise identical to Long-term window
Minimal additional gain over the long-term variant alone; scene flow already captured by the embedding cost.
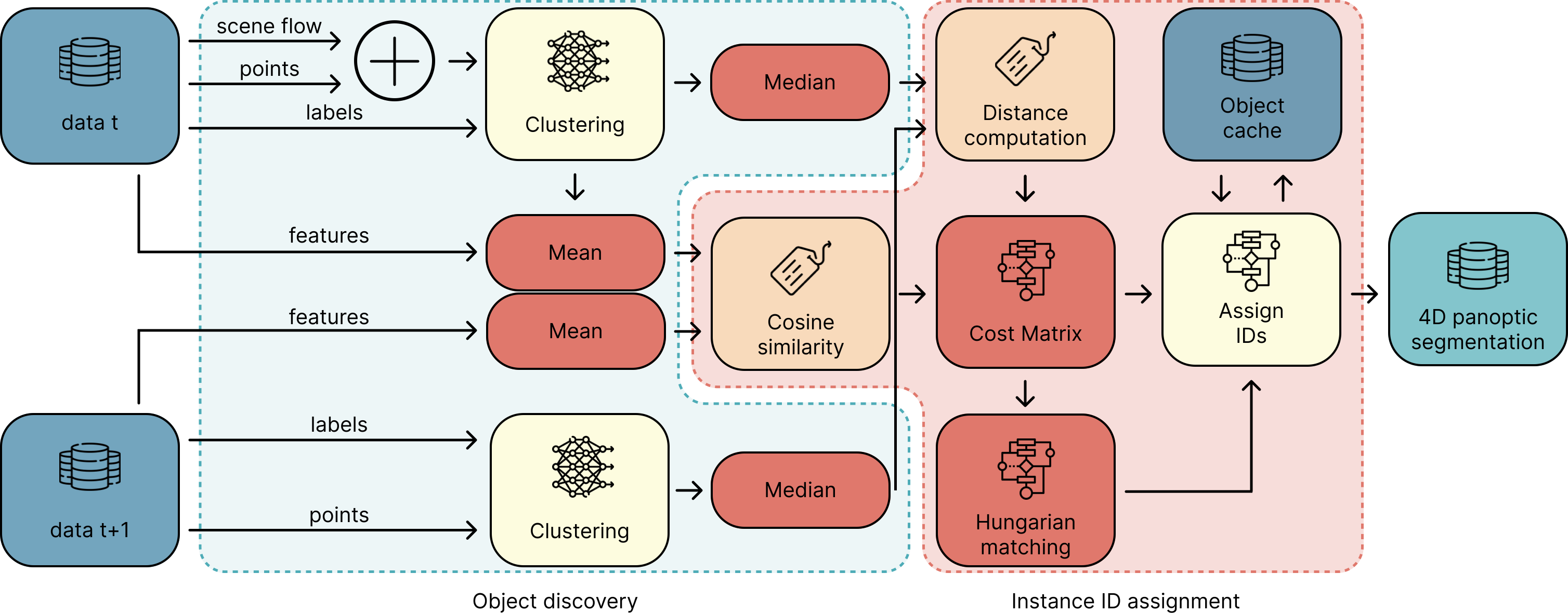
Full association pipeline — object discovery (left) feeds cluster centres and embeddings into the instance ID assignment module (right)
SemanticKITTI
Method progression
DBSCAN gives the best results on SemanticKITTI; HDBSCAN on nuScenes. S_cls is fixed by the semantic model and does not change between association variants.
SemanticKITTI — validation
| Method | LSTQ | S_asc | S_cls |
|---|---|---|---|
| Naive | 42.1 | 31.8 | 55.8 |
| + Scene Flow | 44.7 | 35.9 | 55.8 |
| + Long Window | 46.9 | 39.5 | 55.8 |
| + LW + Scene Flow | 46.9 | 39.5 | 55.8 |
nuScenes — validation
| Method | LSTQ | S_asc | S_cls |
|---|---|---|---|
| Naive | 50.4 | 37.0 | 68.7 |
| + Scene Flow | 47.8 | 33.2 | 68.7 |
| + Long Window | 52.2 | 39.7 | 68.7 |
| + LW + Scene Flow | 52.2 | 39.7 | 68.7 |
Comparison with state of the art
All supervised baselines are trained with full point-level annotations. FlowSeg4D (marked ✓) uses no labels.
- Aygun et al., 4D Panoptic LiDAR Segmentation, CVPR 2021
- Kreuzberg et al., 4D-StOP: Panoptic Segmentation of 4D LiDAR Using Spatio-Temporal Object Proposal Generation and Aggregation, ECCV Workshops 2023
- Marcuzzi et al., Mask4D: End-to-End Mask-Based 4D Panoptic Segmentation for LiDAR Sequences, RA-L 2023
- Yilmaz et al., Mask4Former: Mask Transformer for 4D Panoptic Segmentation, ICRA 2024
- Athar et al., 4D-Former: Multimodal 4D Panoptic Segmentation, CoRL 2023
- Marcuzzi et al., Contrastive Instance Association for 4D Panoptic Segmentation Using Sequences of 3D LiDAR Scans, RA-L 2022
Qualitative results
Semantic segmentation — ground truth (top row) vs WaffleIron linear probing (bottom row) across 5 frames
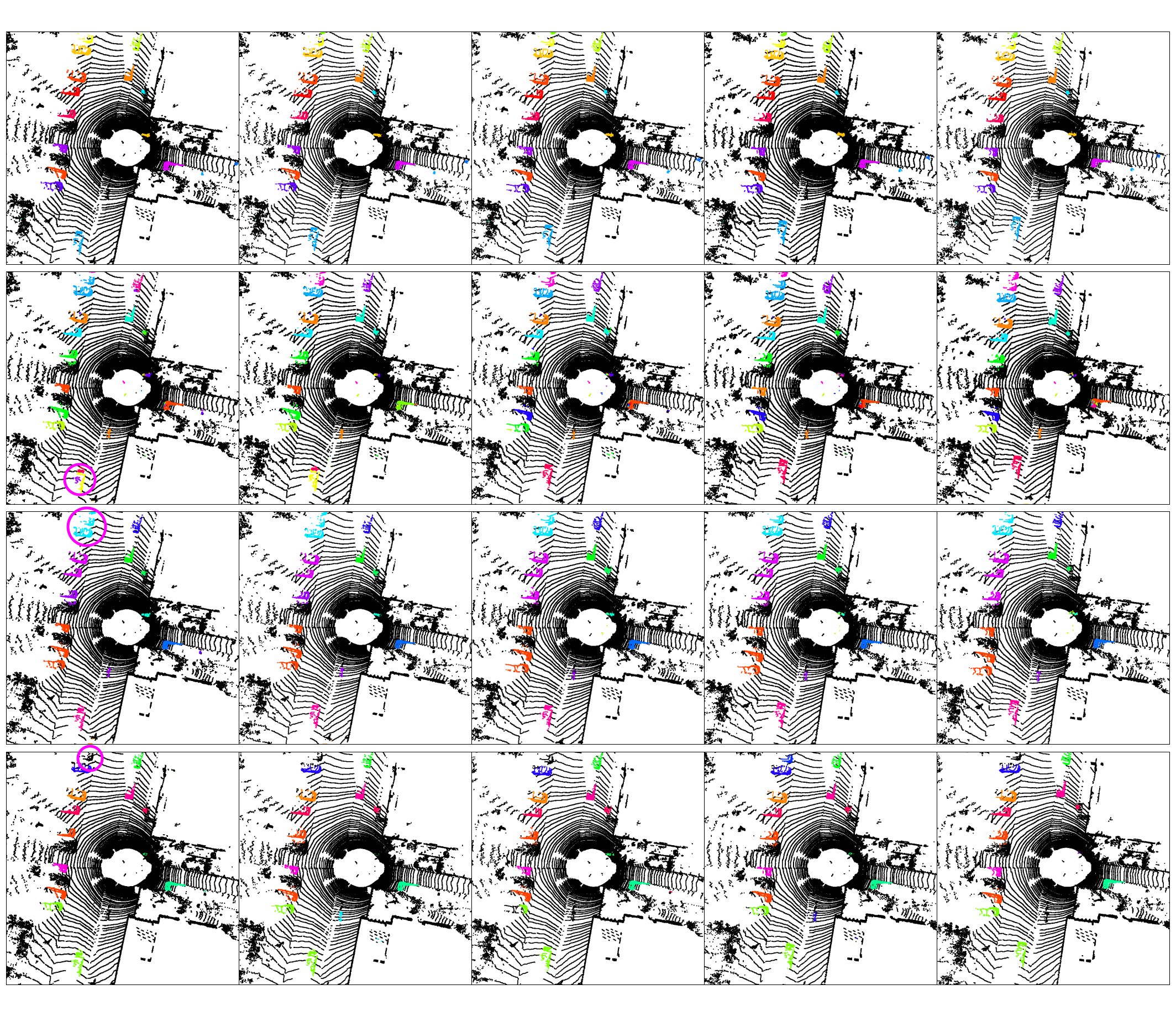
Instance association (long-term + scene flow) — ALPINE (row 1), DBSCAN (row 2–3), HDBSCAN (row 4) across 5 frames. Consistent colour = consistent instance identity.
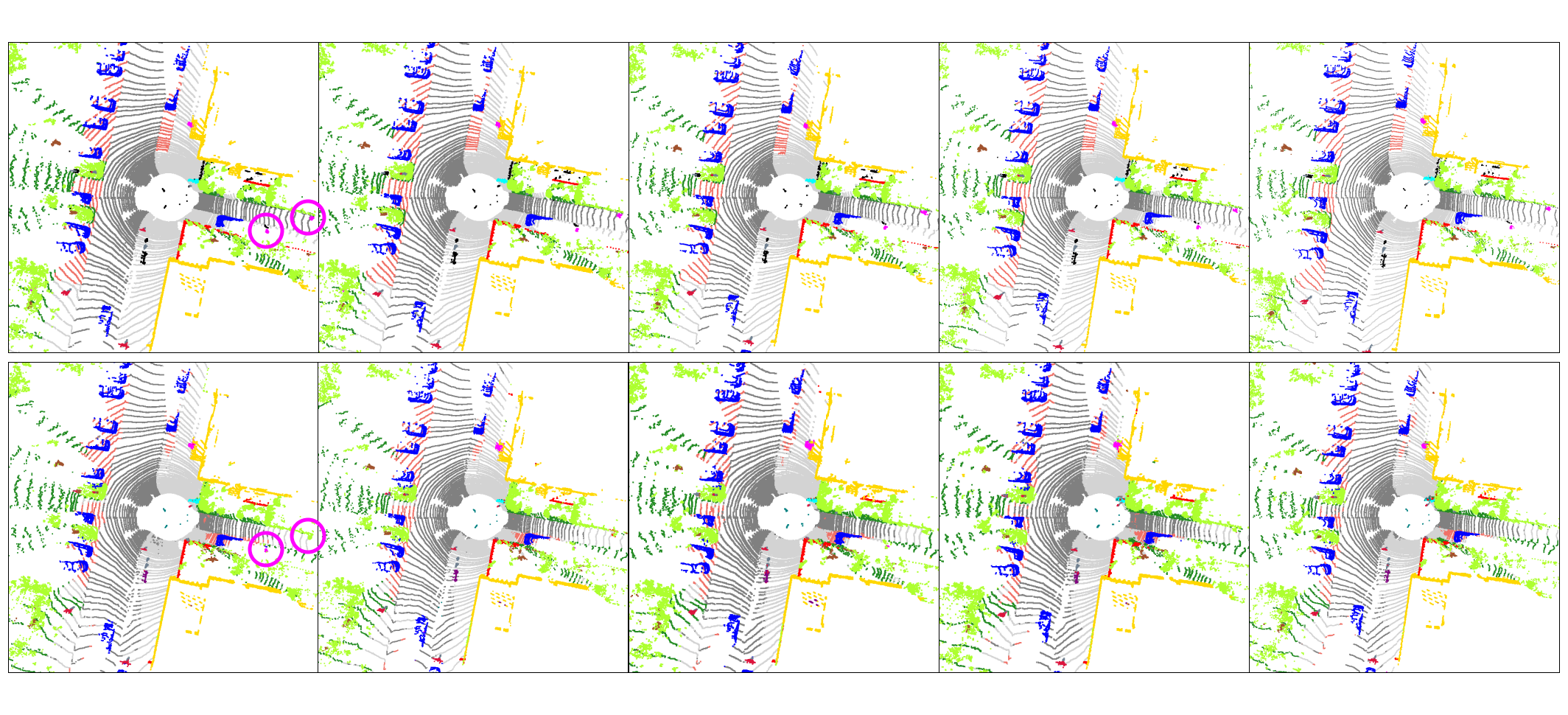
Temporal instance consistency
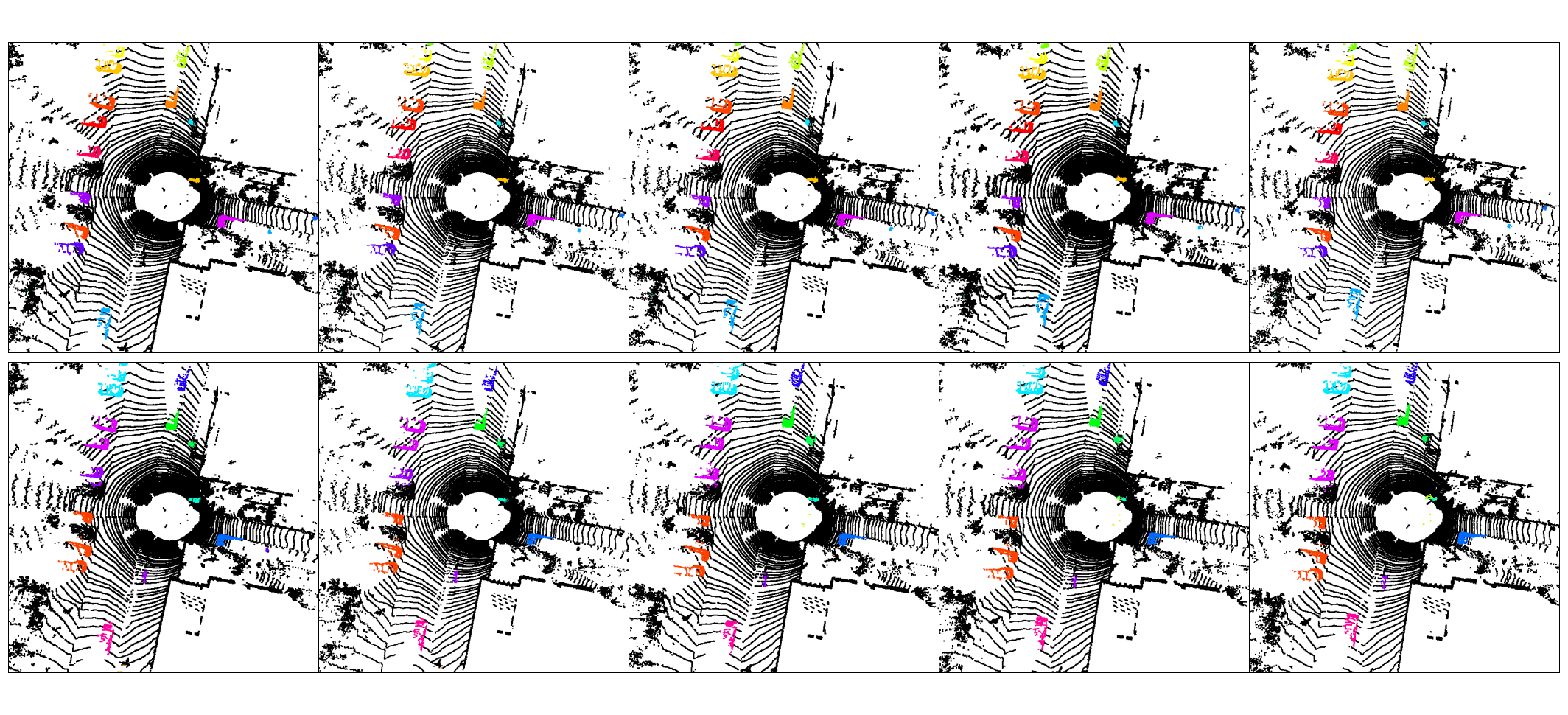
10 consecutive frames — each coloured blob is a tracked instance; consistent colour across frames indicates correct temporal association.
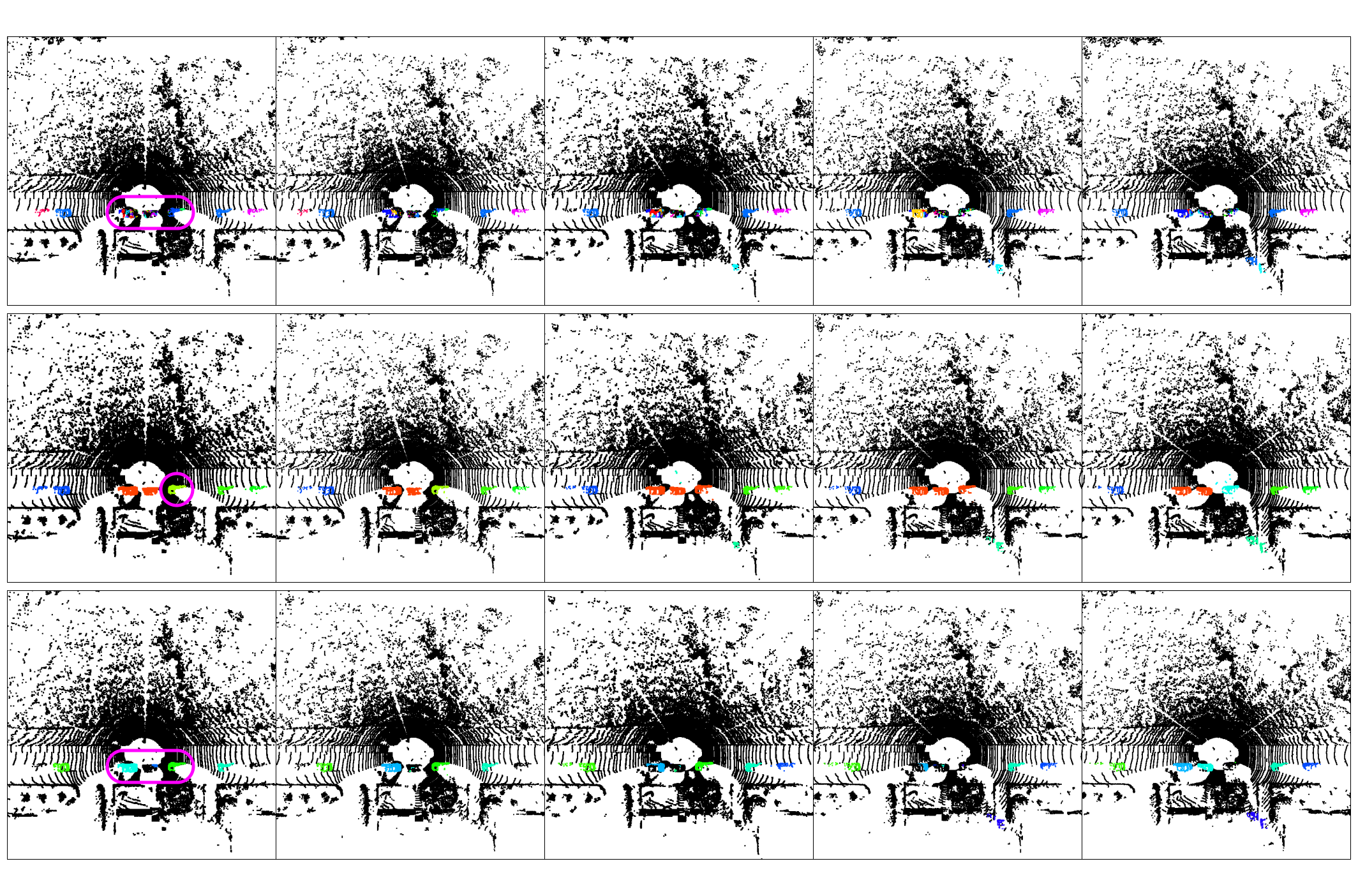
Failure cases
The three clustering methods each exhibit characteristic failure modes. ALPINE (row 1) over-segments; DBSCAN (row 2) merges nearby clusters; HDBSCAN (row 3) struggles with sparse objects.
Cross-dataset generalisation — PONE
FlowSeg4D was applied to the PONE dataset with no retraining or fine-tuning, using models pretrained on SemanticKITTI and nuScenes. Both semantic and instance outputs transfer without adaptation.

Semantic segmentation on PONE — SemanticKITTI model (top row) vs nuScenes model (bottom row) across 3 frames

Instance association (long-term) on PONE — ALPINE (row 1), DBSCAN (row 2), HDBSCAN (row 3)
Master's thesis at CTU FEE, 2025.