FlowSeg4D: Nesupervizovaná 4D panoptická segmentace
Online framework pro 4D panoptickou segmentaci LiDAR scén při řízení, který nevyžaduje žádná anotovaná trénovací data. Kombinuje sémantickou segmentaci, odhad scene flow a temporální clusterování k produkci konzistentních ID instancí pro sledovaní v čase — konkuruje řízeným metodám na benchmarcích SemanticKITTI a nuScenes.
Metoda
4D panoptická segmentace rozšiřuje panoptickou segmentaci na temporální sekvence — každému bodu musí být přiřazena sémantická třída i konzistentní identita instance napříč snímky. FlowSeg4D toho dosahuje bez jakýchkoli labelů kombinací tří komponent.
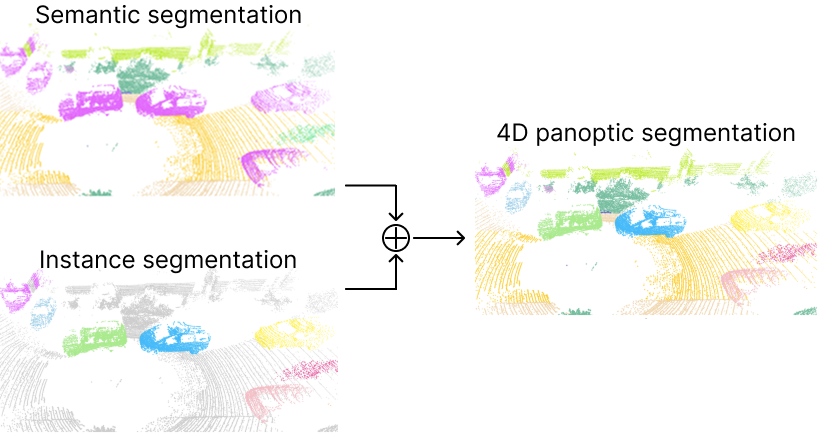
Úloha 4D panoptické segmentace
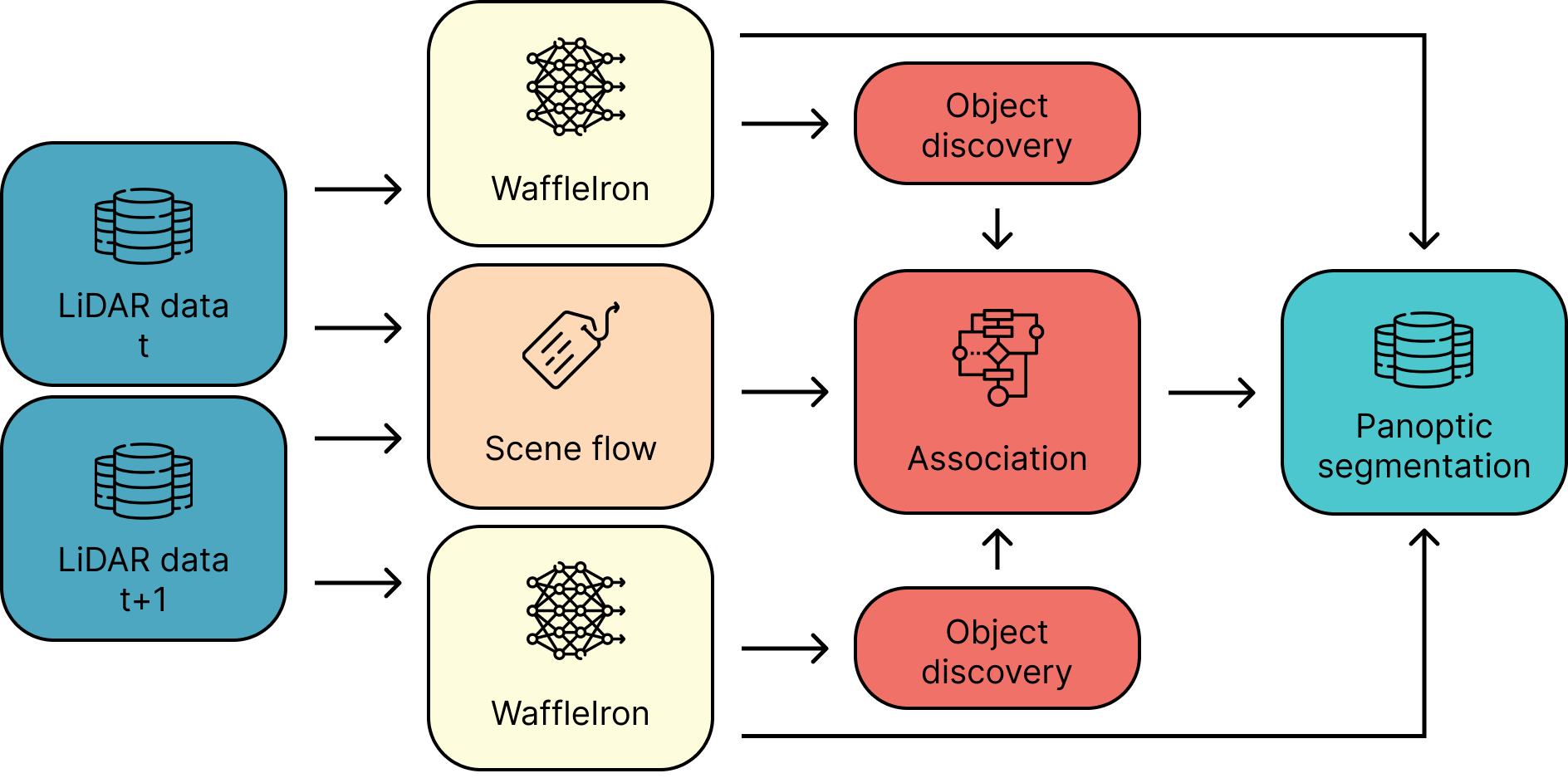
Pipeline FlowSeg4D — sémantická segmentace (žlutá), scene flow (béžová), asociace instancí (červená)
Sémantická segmentace
WaffleIron WI-48-768, předtrénovaný nesupervizovanou metodou ScaLR na čtyřech typech LiDAR senzorů pomocí příznaků DINOv2. Použití linear probing na cílové datové sadě poskytuje třídní labely při minimálních nárocích na anotace.
Odhad scene flow
Let-It-Flow — nesupervizovaný optimalizační model vybraný pro nízkou chybu na zranitelných účastnících silničního provozu (chodci, cyklisté). Vektory scene flow jsou předpočítány a použity modulem asociace k aktualizaci pozic clusterů před přiřazením.
Asociace instancí
Modul clusterování a Hungarian matching, který propojuje objektové clustery napříč snímky. Long-term varianta udržuje temporální okno předchozích snímků a využívá WaffleIron embeddingy spolu s prostorovou vzdáleností k řešení nejednoznačných přiřazení.
Pipeline asociace
Byly vyvinuty a vyhodnoceny čtyři postupně vylepšované strategie asociace. Všechny sdílejí stejný krok clusterování; liší se způsobem přiřazování clusterů napříč snímky.
Naive
- Clusterování sémantických bodů popředí dle třídy (ALPINE / DBSCAN / HDBSCAN)
- Hungarian matching mezi aktuálním a předchozím snímkem s využitím vzdálenosti středů clusterů jako ceny
- Přijetí přiřazení, pokud vzdálenost < 3,5 m → přiřadit stejné ID instance
Rychlá a srozumitelná, ale omezená na jeden předchozí snímek a potýká se s okluzemi.
Naive + scene flow
- Posun středů clusterů o průměrný vektor scene flow před přiřazením
- Jinak shodná s naivní metodou
Zlepšuje výsledky na SemanticKITTI, ale zhoršuje nuScenes — nejefektivnější při nepřesných sémantických labelech.
Long-term okno Nejlepší
- Udržovat okno N předchozích snímků (optimum: 6)
- Reprezentovat každý cluster průměrným WaffleIron embeddingem
- Matice nákladů = vzdálenost středů + nesimilarita příznaků (1 − cosinova podobnost), vážená α = 0,1
- Hungarian matching; přijmout pouze při splnění obou podmínek — vzdálenost (< 4,5 m) a práh příznaků (nesimilarita < 0,4)
Konzistentní zlepšení oproti naivní metodě na všech datových sadách a metodách clusterování.
Long-term + scénový tok
- Aktualizovat středy clusterů předchozího snímku průměrným scene flow před přiřazením
- Jinak shodná s metodou Long-term okno
Minimální přínos oproti samotné long-term variantě; scene flow je již zachycen v ceně embeddingu.
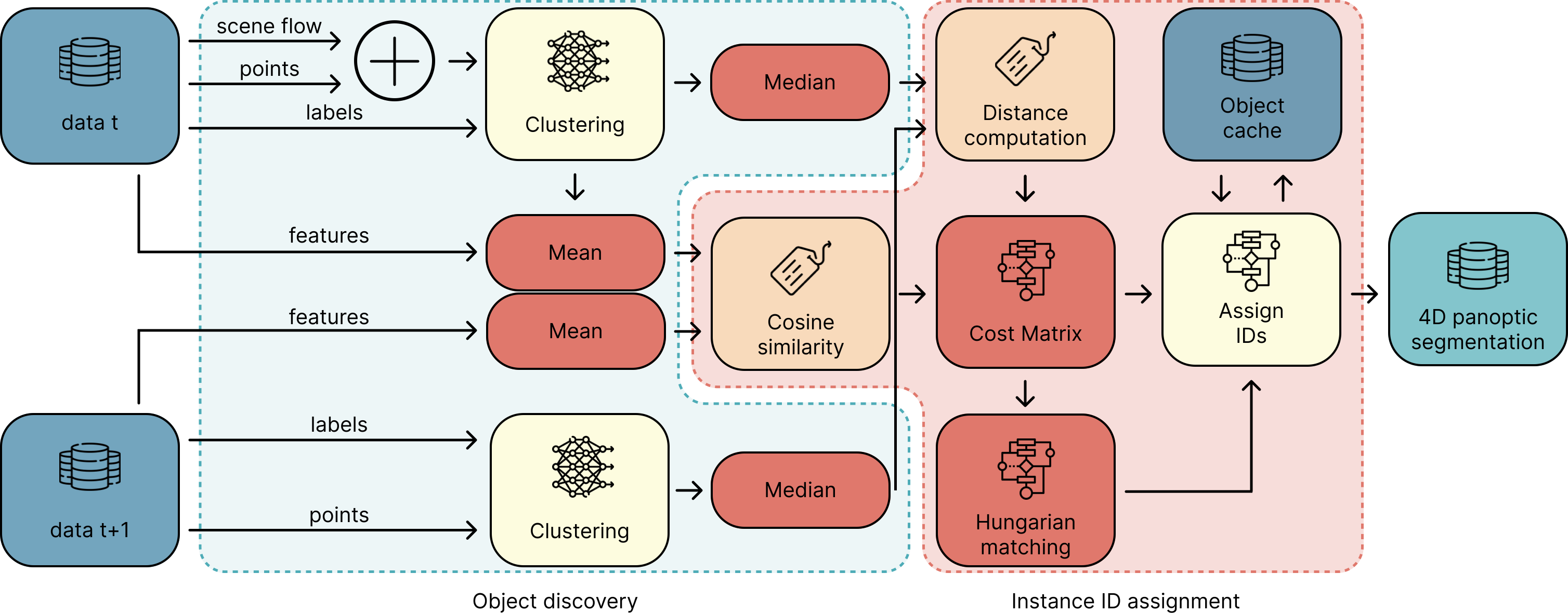
Kompletní asociační pipeline — detekce objektů (vlevo) předává středy clusterů a embeddingy do modulu pro přiřazování ID jednotlivých instancí (vpravo)
SemanticKITTI
Vývoj metody
DBSCAN dosahuje nejlepších výsledků na SemanticKITTI; HDBSCAN na nuScenes. S_cls je dán modelem na sémantickou segmentaci a nemění se mezi variantami asociace.
SemanticKITTI — validace
| Metoda | LSTQ | S_asc | S_cls |
|---|---|---|---|
| Naive | 42,1 | 31,8 | 55,8 |
| + scene flow | 44,7 | 35,9 | 55,8 |
| + long. okno | 46,9 | 39,5 | 55,8 |
| + LO + sc. flow | 46,9 | 39,5 | 55,8 |
nuScenes — validace
| Metoda | LSTQ | S_asc | S_cls |
|---|---|---|---|
| Naive | 50,4 | 37,0 | 68,7 |
| + scene flow | 47,8 | 33,2 | 68,7 |
| + long. okno | 52,2 | 39,7 | 68,7 |
| + LO + sc. flow | 52,2 | 39,7 | 68,7 |
Srovnání se stavem umění
Všechny metody jsou trénovány s anotacemi na úrovni bodů. FlowSeg4D (označen ✓) nepoužívá žádné anotace.
- Aygun et al., 4D Panoptic LiDAR Segmentation, CVPR 2021
- Kreuzberg et al., 4D-StOP: Panoptic Segmentation of 4D LiDAR Using Spatio-Temporal Object Proposal Generation and Aggregation, ECCV Workshops 2023
- Marcuzzi et al., Mask4D: End-to-End Mask-Based 4D Panoptic Segmentation for LiDAR Sequences, RA-L 2023
- Yilmaz et al., Mask4Former: Mask Transformer for 4D Panoptic Segmentation, ICRA 2024
- Athar et al., 4D-Former: Multimodal 4D Panoptic Segmentation, CoRL 2023
- Marcuzzi et al., Contrastive Instance Association for 4D Panoptic Segmentation Using Sequences of 3D LiDAR Scans, RA-L 2022
Kvalitativní výsledky
Sémantická segmentace — ground truth (horní řada) vs lineární sondování WaffleIron (dolní řada) napříč 5 snímky
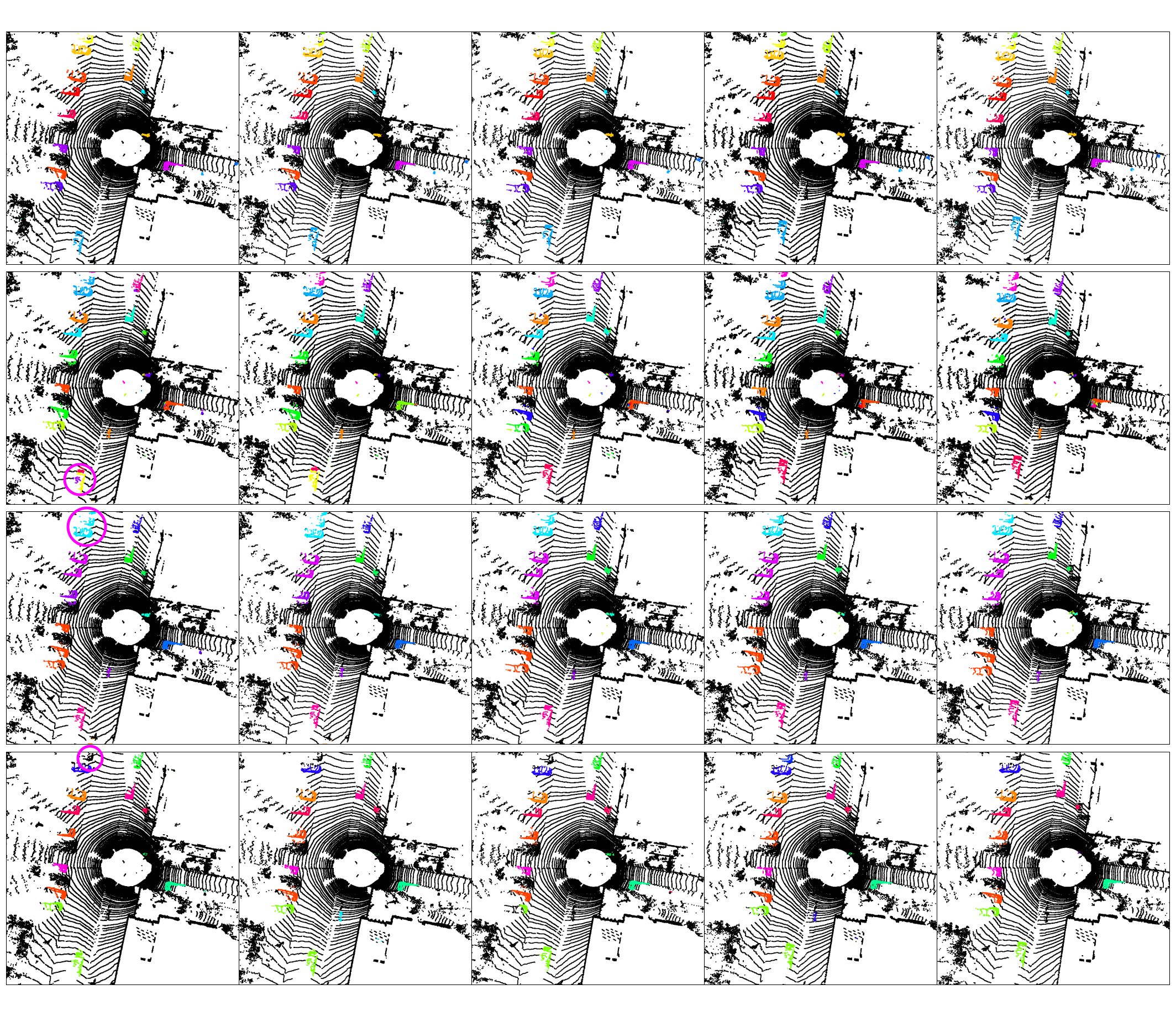
Asociace instancí (long-term + scénový tok) — ALPINE (řada 1), DBSCAN (řady 2–3), HDBSCAN (řada 4) napříč 5 snímky. Konzistentní barva = konzistentní identita instance.
Temporální konzistence instancí
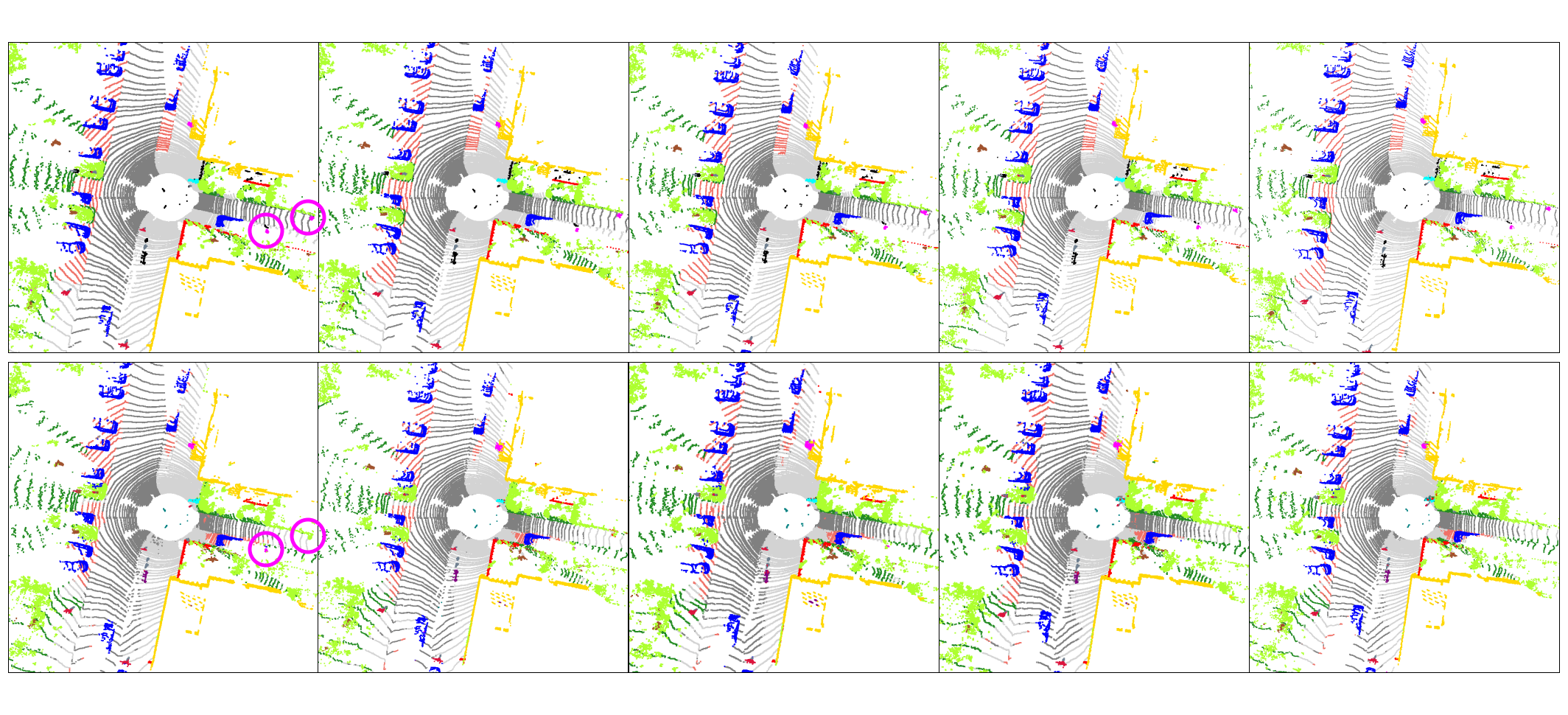
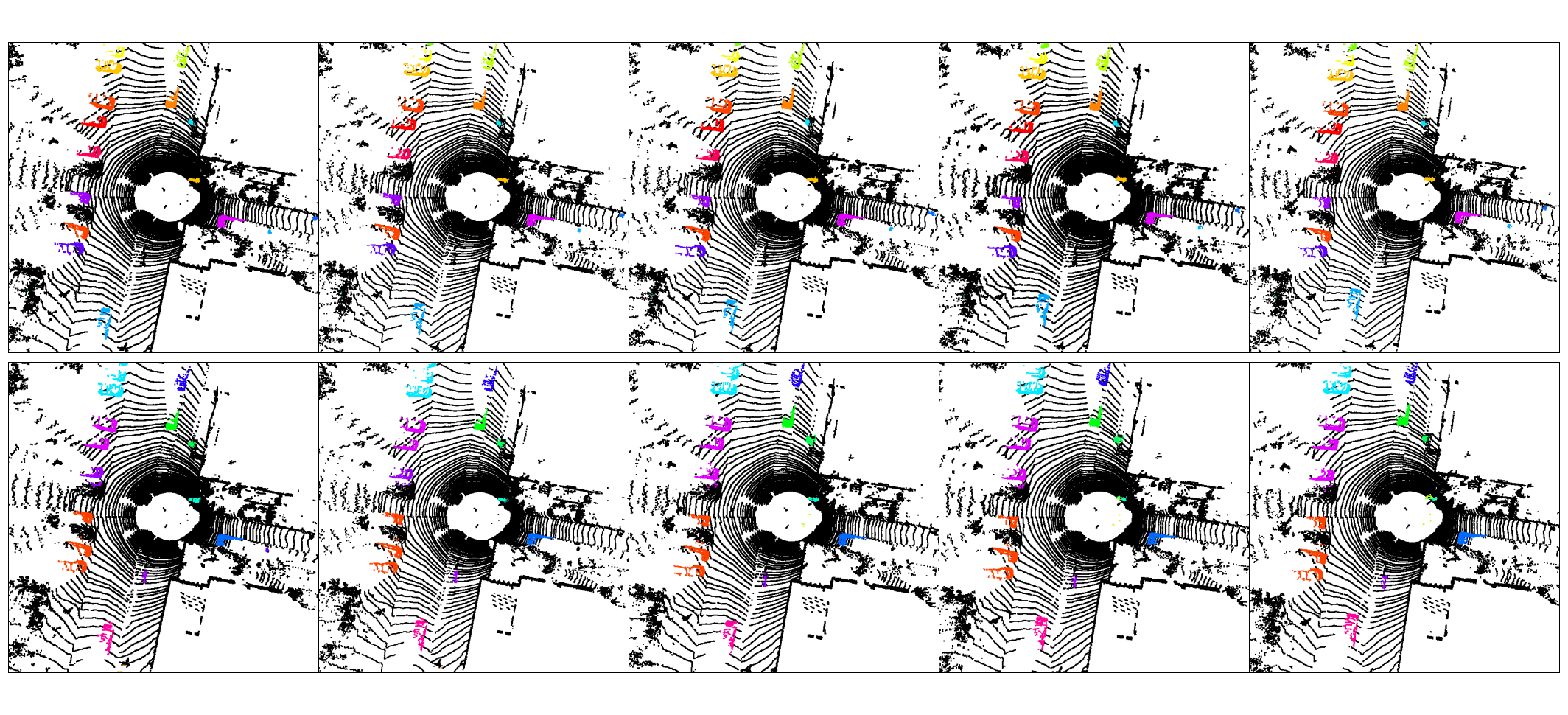
10 po sobě jdoucích snímků — každý barevný shluk je sledovaná instance; konzistentní barva napříč snímky indikuje správnou temporální asociaci.
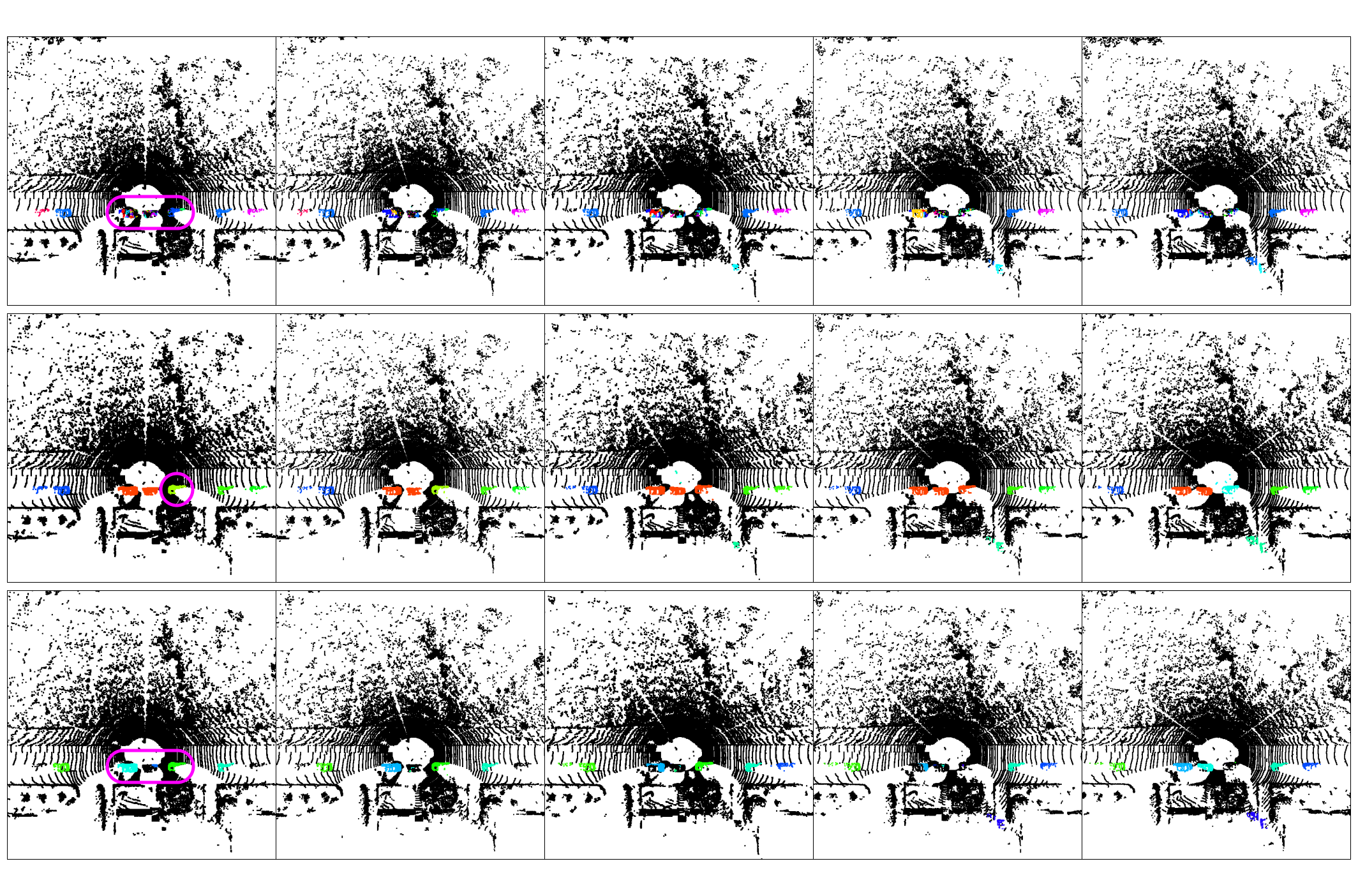
Případy selhání
Každá metoda clusterování vykazuje charakteristické typy selhání. ALPINE (řada 1) nadměrně segmentuje; DBSCAN (řada 2) slučuje blízké clustery; HDBSCAN (řada 3) má potíže s řídkými objekty.
Generalizace napříč datovými sadami — PONE
FlowSeg4D byl aplikován na datovou sadu PONE bez přetrénování nebo doladění, s využitím modelů předtrénovaných na SemanticKITTI a nuScenes. Jak sémantické, tak instanční výstupy se přenesou bez adaptace.

Sémantická segmentace na PONE — model SemanticKITTI (horní řada) vs model nuScenes (dolní řada) napříč 3 snímky

Asociace instancí (long-term) na PONE — ALPINE (řada 1), DBSCAN (řada 2), HDBSCAN (řada 3)
Diplomová práce na FEL ČVUT, 2025.